How to build AI support agents that don't suck

Here’s a question for you: how do you make AI support agents that don’t suck? Gizmo Support Dashboard is the answer I've been cooking up over the past few weeks for that particular issue we have here at Gadget.
The goal is a system that automates initial investigation and allows for easy feedback from our knowledgeable support engineers to modify and update potential responses.
While agents have access to the publicly available docs, they have no understanding of the Gadget core monorepo or any of the code powering users’ applications. Previous attempts at support automation via agents have been quite poor, as any question that is not answerable with a docs link becomes out of scope. And to be fair, the docs are public, so you could just ask your own AI agent to search them instead.
A bit of background: Gadget is an infraless software development platform. APIs are tightly coupled to the underlying fullstack app infrastructure. This makes it simple to deploy and scale applications, and means we provide features like background jobs or ElasticSearch on demand.
This is why it is so important for a system like this to use agents with the context of not only our monorepo, but also our users’ application code plus logs, analytics, trace IDs, etc. Questions like “why am I getting X error” or “what does X log mean” or often important billed metrics, like “why is my worker utilization so high” may require the agent to pull trace information from ClickHouse and monorepo code to determine if there is a bug with the platform or the user’s implementation. This is what our support engineers do manually today!
So then the obvious solution is to give the agent access to the Gadget codebase, right? Well, yes, but it's a little more complicated than that. Where does this agent live? How does it manage multiple tickets coming in at a time? How do we make all this fast and efficient? And the big question what about users apps? The old way was that a support engineer had to have the Gadget codebase on their local machine. They opened a couple of instances of Claude Code or their preferred agent in something like Zellij, copied the ticket in, and got a draft output, which they could then verify, edit, and send on its way. The problem with that is it's annoying and slow. You can only answer 2-3 tickets at a time, and it's hard to keep track of everything.
Think of the Gizmo Support Dashboard as your one-stop shop for agentic support ticket workflows. A ticket comes in on Pylon, our support management software, which fires off a webhook to the Gizmo Support Dashboard (and webhooks are also fired on any message or update to the ticket). We ingest that webhook and create a ticket in our dashboard. Next, we spin up an E2B sandbox.
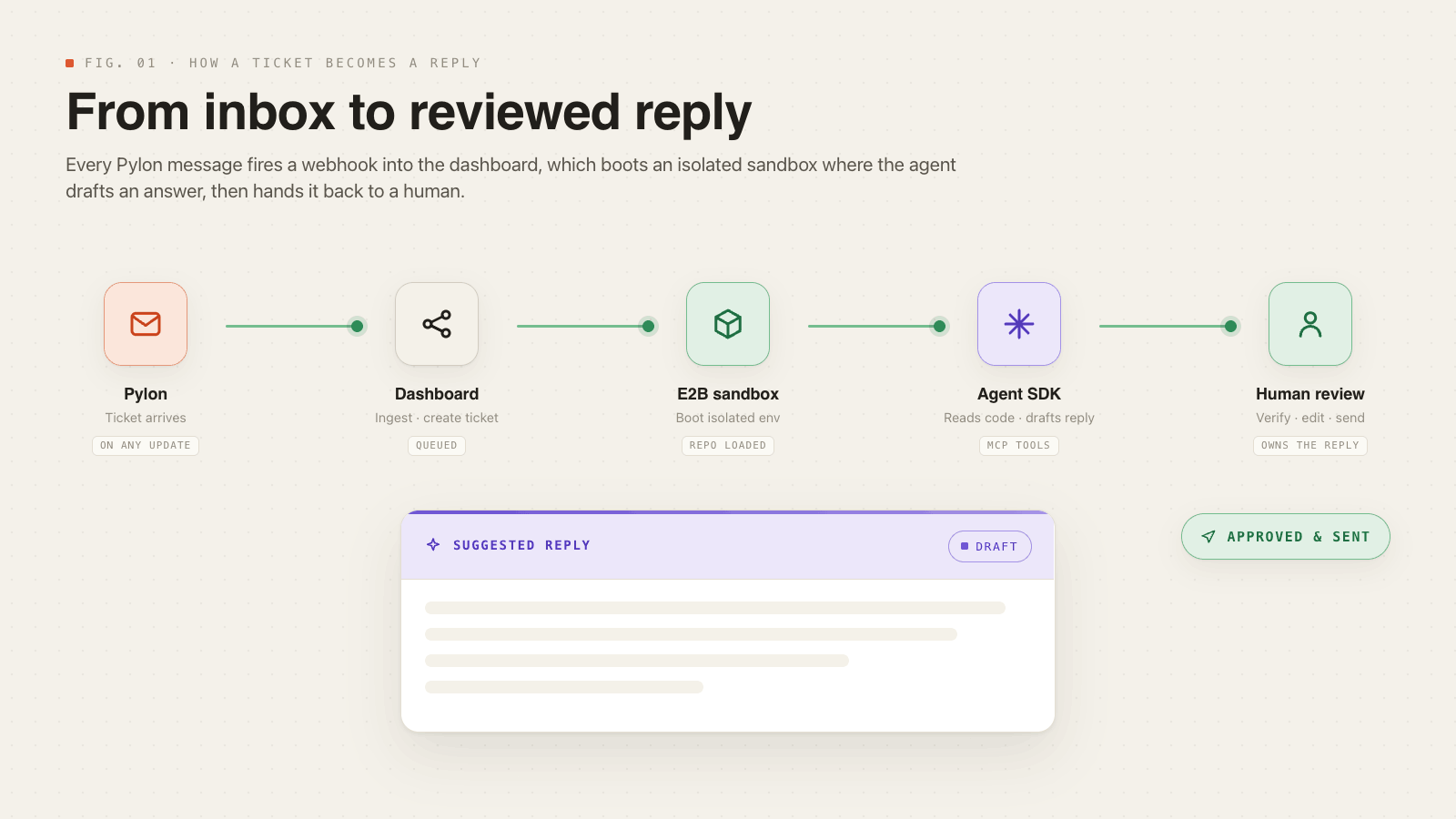
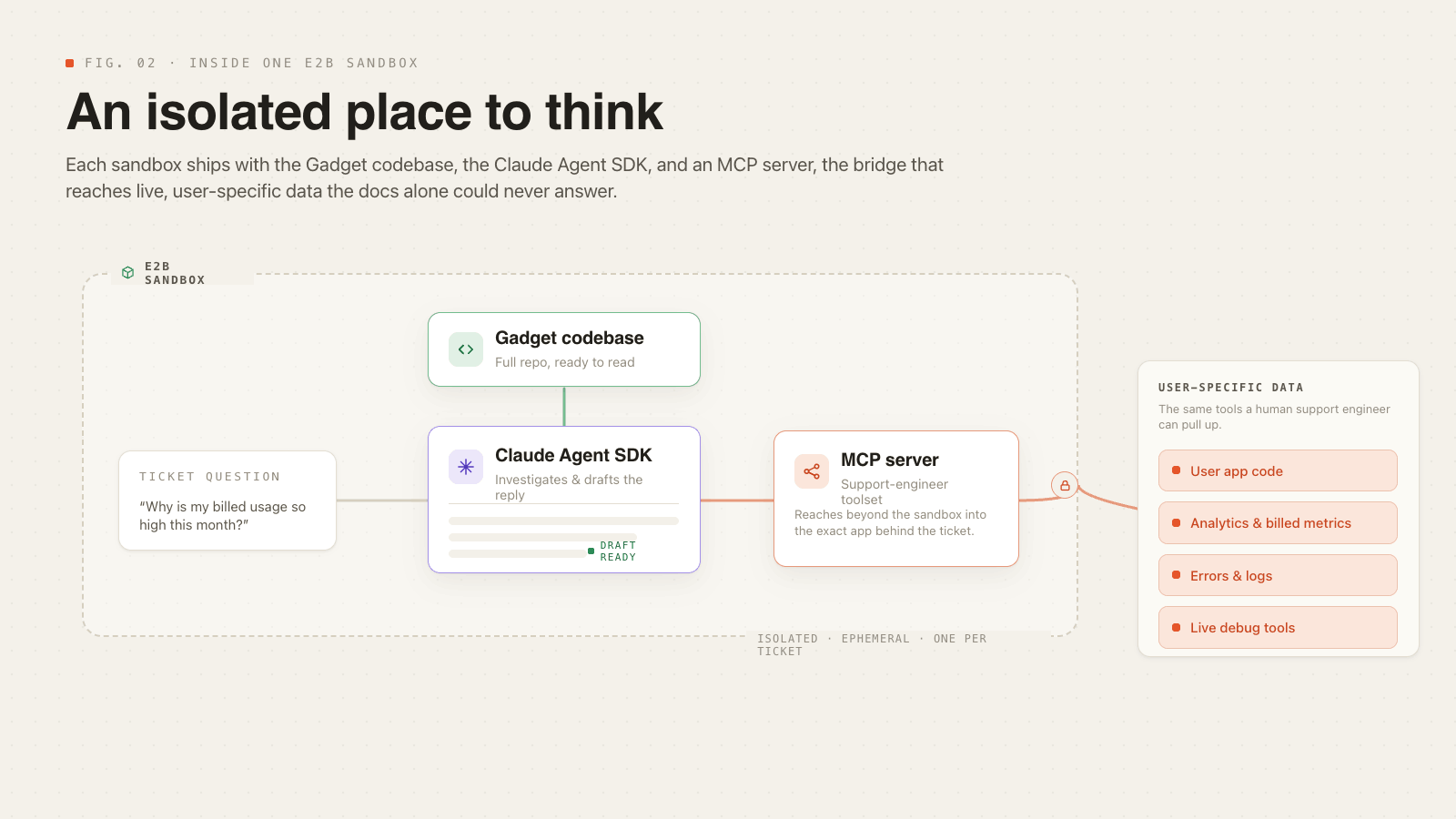
E2B is what they call an agent sandbox; think of it like a Docker container. An isolated place for the agent to complete its work that can be spun up and down whenever we wish. This sandbox has the Gadget codebase, the Claude Agent SDK, and a special MCP server that allows the agent to actually access users’ app code and all the analytics that a support engineer would have access to. E2B makes this extreamly simple:
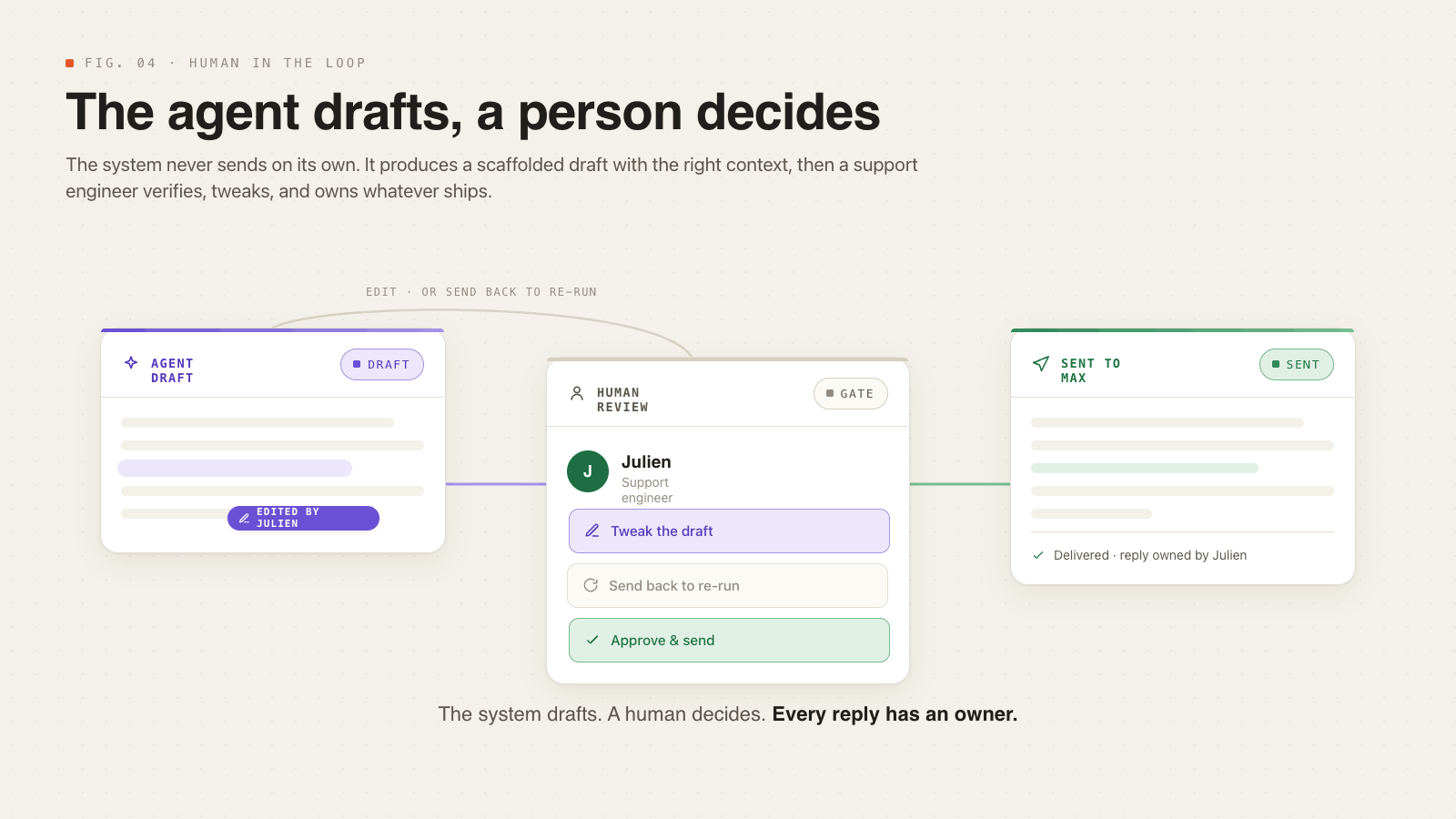
Once it's booted up, the agent SDK is given the user's question along with some system prompts and rules, and sent off into the codebase to draft an answer. That answer is then streamed back to the dashboard, where it is presented as a draft for user review.
This isolated image approach solves basically all of the problems we had back when support engineers had to do this job manually. Another nice side effect is that because there isn't just one Claude Agent SDK with the Gadget codebase running, we can answer any number of tickets at once. If we get 1000 tickets all at once, all we have to do is spin up 1000 sandboxes, and each has its own isolated, independent place to answer the question.

Next, let's talk about that final piece of the puzzle, the special MCP server that takes this system from a clumsy but educated response to an actual user-specific answer with context and information about that exact issue on that exact app. Essentially, this MCP gives the model access to all the same tools for debugging and answering questions that human support engineers at Gadget have access to. This allows the model to dive into user-specific code, analytics, and other information often necessary for answering Gadget support tickets.
Overall, this system is not meant to replace human support engineers, as someone has to be responsible for what goes out. The system can generate drafts, but at the end of the day, a human might still be required, even if just to validate the agent's work. It's meant to speed up the time to response by providing a scaffold and relevant information. It can sometimes generate a complete response, but I would be very surprised if some small edits weren't needed.



