Zero downtime Postgres upgrades using logical replication

Our core database was running on PostgreSQL 13, and its end of life was approaching quickly.
This database handled two critical workloads: it stored user application data for thousands of ecommerce apps (powering functionality on 100K+ stores) and also served as our internal control plane, holding state, configuration, and user billing information. Any downtime would have disrupted live storefronts and broken integrations in production.
Instead of performing a traditional in-place upgrade that requires a variable amount of downtime, we implemented an upgrade process that relied on logical replication and PGBouncer. The cutover was seamless, with zero disruption to our users and zero data consistency issues: our target Postgres 15 instance took over from the production Postgres 13 database while avoiding any disruption to live traffic.
Here’s how we did it.
We want to thank our friends at PostgresAI for helping us devise our upgrade strategy and for being on deck just in case we needed them during what ended up being a 3-second changeover. They were instrumental in designing a procedure that would allow us to upgrade Postgres with zero downtime and zero data loss, and were with us from the very start of the process through final execution.
We leaned on them pretty heavily to help prototype different strategies to perform the database synchronization and upgrade. Their deep subject matter expertise and experience orchestrating a similar procedure across GitLabs’ fleet of Postgres servers helped us avoid a lot of pitfalls.
The problem with a traditional upgrade
Our core database was a single PostgreSQL 13 instance containing all production data, managed by CrunchyData. Crunchy’s replica-based upgrade process is roughly:
- Create a candidate instance from an existing backup (that is a replica of the primary instance).
- Allow the candidate instance to catch up and get in sync with the primary.
- During this time, the primary instance is still fully writable.
- The upgrade of the candidate instance is performed.
- The primary instance is made inaccessible during the upgrade.
- Upon successful upgrade of the candidate instance, it is promoted to being the primary and is once again accessible to clients.
- If the upgrade of the candidate instance fails for any reason, the primary instance will resume and serve clients again.
There is unavoidable downtime that typically lasts anywhere between a couple of seconds to a few minutes.
We tested this replica-based upgrade on our database: it required hours of downtime due to the massive number of required catalog updates and index rebuilds, and needed manual intervention from the Crunchy team.
The conventional approach would have introduced an unacceptable window of unavailability. We needed a solution that allowed us to keep processing reads and writes during the upgrade.
Why not schedule a maintenance window?
Continuous availability is a non-negotiable requirement. Gadget supports high-volume operations for thousands of production applications. An outage would mean a loss of app functionality across +100,000 Shopify stores. Our Postgres upgrade needed to avoid dropped connections, timeouts, and data inconsistency. We could not rely on strategies that temporarily blocked writes or froze the database.
Early replication challenges
A replica-based process using physical replication and an in-place upgrade was not an option, so we explored upgrade paths that involved using logical replication between the primary instance and an upgraded candidate instance.
We knew that if we kept our upgraded candidate instance in sync with the primary, the upgrade could be done out of band. We would still need to manage dropped connections and data integrity during the cutover, but could avoid the major source of downtime.
But relying entirely on logical replication introduced two issues:
- Logical replication does not automatically update sequence values on the candidate instance, which can lead to duplicate key errors if the sequence on the candidate instance is behind the source. Without careful handling, logical replication can fail when inserts on the promoted candidate instance encounter primary key conflicts. More details on our sequencing problem are available at the end of this post.
- Relying entirely on logical replication introduced one major issue: logical replication requires the database schema to remain stable during the entire process. Part of Gadget’s value is that customers have full control of their application’s schema. This means that user-driven DDL (data definition language) changes are happening all the time. Using logical replication while allowing schema modifications would be impractical because every schema change would have to be detected, applied to the candidate instance, and then logical replication could be resumed without loss of consistency.
DDL changes could potentially be handled using event triggers, but that would add an additional layer of complexity we wanted to avoid. The "easiest" path forward involved removing the user-made DDL changes from the equation – we could shard the data out into a separate database.
Sharding to simplify replication
Instead of managing the upgrade around the constraints of user-defined database schemas, we decided to avoid the problem entirely.
We migrated the bulk of user application data to AlloyDB shards. (Because hey, sharding the database was on the to-do list anyway.)
I won’t go into the sharding process here; that’s a whole other post. But we were able to reduce our core database size from ~7TB down to ~300GB. Post-shard, all that remained was our internal-only, non-customer-facing, control-plane data. With the remaining schema now internal, under our control, and effectively immutable during the upgrade, upgrading with logical replication became a practical option.
The dramatic reduction in storage size is what enabled us to rely solely on logical replication. If this size reduction was not possible, we would have had to start with physical replication, then cut over to logical replication to finish the upgrade.
Building the candidate database
Now we could finally start the actual upgrade process.
We created a candidate database from a production backup. This ensured the candidate included all roles, tables, and indexes from production.
To simplify replication reasoning, we truncated all tables (dropped all data) so that the candidate database was empty. Truncating gave us a blank slate to work with: we could lean on Postgres’ tried and true, built-in replication mechanism to backfill existing data and handle any new transactions without the need for any kind of custom replication process on our end.
Then we upgraded the candidate instance to PostgreSQL 15 and started logical replication from our primary instance. As a result, the candidate Postgres 15 instance remained fully consistent with the primary instance throughout the process.
Planning the switchover
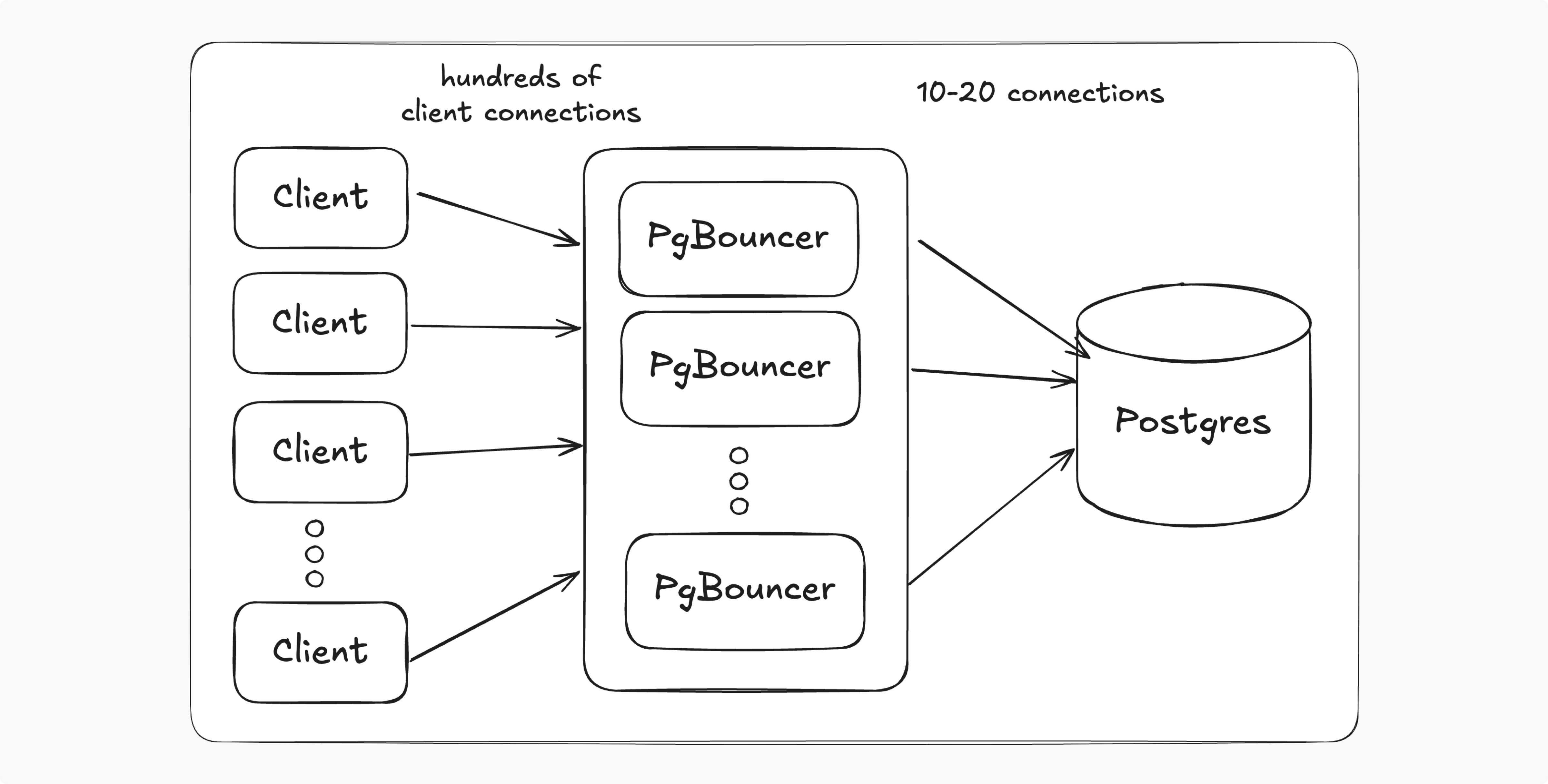
Our production system routes all connections to the database through PgBouncer running in Kubernetes. We run multiple instances of PgBouncer across nodes and zones for redundancy.
Each instance of PgBouncer limits the number of direct connections to the database. Hundreds of clients connect to PgBouncer and PgBouncer orchestrates communication with the database using 10-20 connections. This provided a convenient choke point for controlling writes during the switchover. PgBouncer also happens to have a handy pause feature, which allows all in-flight transactions to complete while holding any new transactions in a queue to be processed (when resumed).
We’re fans of Temporal here at Gadget, so we built a Temporal workflow to coordinate the switchover. The workflow performed preflight checks to verify permissions, ensure replication lag was not too high, double-check sequence (unique ID) consistency, and validate changes to the PgBouncer configuration.
Our plan for the changeover: start by running the preflight checks and then pause all PgBouncer instances, letting any active transactions complete. Once all PgBouncers were paused, we could make the primary instance read-only to be extra sure that we would not hit any data consistency issues if the switch-over did not go as planned. With all of this done, we would be in a state where writes could no longer occur on the current primary instance.
At this point, we should be able to cutover to the candidate instance. We would need to wait until the replication lag between the primary and candidate instance was at 0, meaning the candidate was fully caught up, update the <inline-code>pgbouncer.ini<inline-code> file via a Kubernetes configmap, loop over all PgBouncer instances to reload their configuration, and validate that each PgBouncer was pointing to the candidate instance instead of the primary.
And all that should happen without any dropped connections.
We wanted to test this out before we upgraded our core database.
Testing and iteration
This database (and the Alloy shards) are not the only databases we manage here at Gadget.
Great, plenty of test subjects for our upgrade process.
We started with low-impact databases that had no impact on end users: our CI database and internal Redash database. Once those upgrades were successful, we moved on to databases that carried a bit more risk: we upgraded the Temporal database responsible for our end users' enqueued background jobs. An outage would impact end users, but we could also roll back without violating any SLOs. Once that was successful, we upgraded our Dateilager database. This stores our users’ code files and project structure (and, as you may have guessed, does have user impact) and was our final test run before upgrading our core database.
Our initial preflight check encoded verification of the basics:
- We had permissions to use the Kubernetes API.
- We could contact and issue commands to all PgBouncer instances.
- We could connect to the primary and candidate Postgres instances.
- A new <inline-code>pgbouncer.ini<inline-code> config file was present.
Believe it or not, we didn’t nail our suite of preflight checks on the first attempt. Testing the process on multiple databases helped us build a robust preflight check and allowed us to check for problems like:
- Ensuring both the subscription owner and database owner were usable by the workflow and had the appropriate permissions. We had an issue where our upgrade would fail halfway through because the user we connected to the candidate instance with did not have the permissions to disable the logical replication subscription.
- Guarantee that our sequences were correct on the candidate instance. We also needed to check that we had access to all sequences present on the primary on the candidate. Additionally, we checked that we could update all sequences on the candidate instance to the values of the primary instance. We caught an issue where a sequence name had a specific casing, <inline-code>mySequence<inline-code>, on the primary instance, and we were trying to set <inline-code>mysequence<inline-code> (all lowercase) on the candidate instance, causing the workflow to fail.
- Validate that the <inline-code>pgbouncer.ini<inline-code> file has the correct configuration parameters. When running against one of the initial databases, we didn’t update <inline-code>pgbouncer.ini<inline-code> to point to the new candidate instance. Our workflow ended up in an infinite loop while our PgBouncers were paused. Queries were taking too long. Clients eventually timed out. So we added a check to guarantee the db stanza was the only thing changed.
- We added a <inline-code>dry-run<inline-code> option to our workflow, allowing us to iterate on our preflight checks. This option would only run the preflight checks, then pause and resume the PgBouncer instances. This worked great when we remembered to set <inline-code>dry-run<inline-code> to <inline-code>true<inline-code>. On one iteration, <inline-code>dry-run<inline-code> was accidentally set to <inline-code>false<inline-code> and ran the actual switchover on a database. Fortunately, the switchover worked. This happy little accident led to an additional checksum added to the workflow (based on the <inline-code>pgbouncer.ini<inline-code> config) that verified that you really wanted to apply the new config.
We incorporated validation steps for each issue into the workflow and augmented our test suite to check for these issues, which helped to ensure we would not regress.
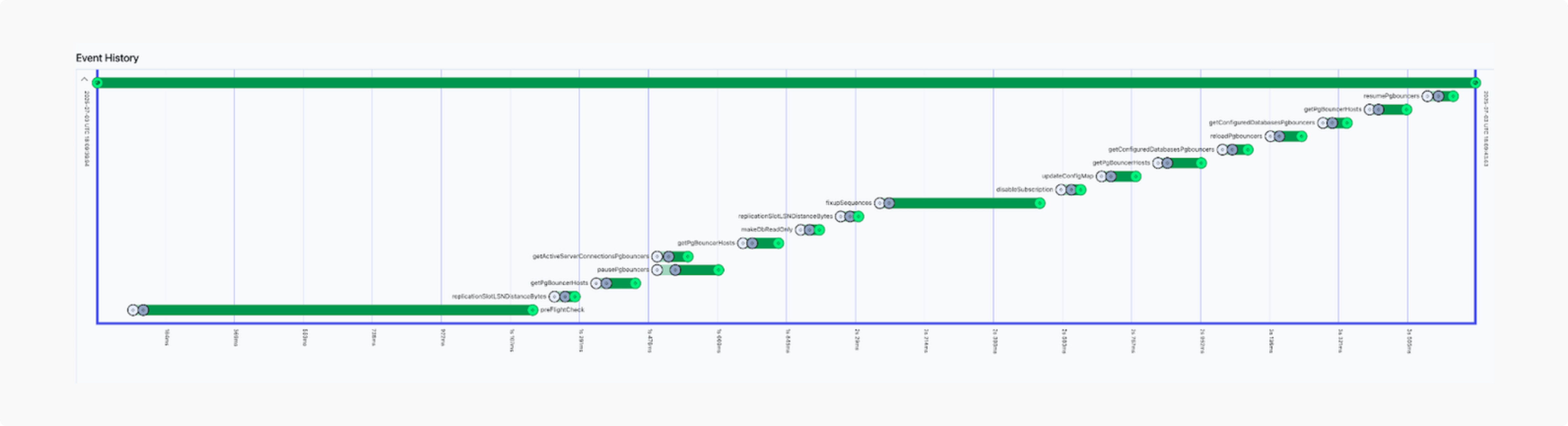
The final workflow
Here’s a high-level overview of our final temporal workflow:
function CutoverDatabase(params):
// Extract parameters and set defaults
// configure namespace and replication thresholds
// Step 1: Run pre-flight checks
result = run preFlightCheck(...)
if checks failed:
throw error and stop
// Step 2: Ensure replication lag is small enough
// before starting wait until replication lag < threshold
check for replication lag < threshold
if checks fails:
throw error and stop
// Step 3: Gather list of PgBouncer hosts
pgbouncerHosts = getPgBouncerHosts(...)
try:
// Step 4: Pause PgBouncer traffic and wait
// for connections to drain
pauseAndWait(pgbouncerHosts)
if not in dry-run mode:
// Step 5: Put primary database into read-only mode
makeDbReadOnly()
// Step 6: Wait until replication lag = 0
wait until replication lag = 0
// Step 7: Sync/fix database sequences
fixupSequences()
// Step 8: Disable subscription (pause replication)
disableSubscription()
// Step 9: Update PgBouncer configuration
// so new traffic points to candidate
updateConfigMap()
// Step 10: Refresh list of PgBouncer hosts
pgbouncerHosts = getPgBouncerHosts(...)
// Step 11: Reload PgBouncers and verify connections
// now target the new candidate
reloadAndVerify(pgbouncerHosts)
finally:
// Step 12: Resume PgBouncers regardless of success/failure
pgbouncerHosts = getPgBouncerHosts(...)
resumePgbouncers(pgbouncerHosts)
return successcheck for replication lag < thresholdif check fails: throw error and stop
Surely nothing would go wrong when upgrading production.
The final cutover
That’s right, nothing went wrong. The switchover to the upgraded Postgres 15 database took all of 3 seconds. All the client connections were maintained and there were no lost transactions.
Nobody, neither Gadget employees nor developers building on Gadget, experienced any timeouts, 500s, or errors of any kind.

It took longer to get our infrastructure team in the same room and ready to fire-fight just in case.
Engineers from PostgresAI were on standby with us in case anything went really wrong. But the zero-downtime upgrade succeeded before we could switch to the Temporal UI to watch its progress. We had addressed schema stability, replication integrity, sequence correctness, and connection pooling in advance. And we ran dozens and dozens (and dozens) of <inline-code>dry-runs<inline-code> over multiple databases to ensure the workflow was robust and all of the different entities were in a known state so that the workflow could run without a hitch.
Closing thoughts
The upgrade process demonstrated that it is possible to upgrade a complex, high-availability Postgres environment without impacting users.
Sharding reduced database complexity and enabled us to rely on vanilla logical replication. Iterative testing on lower-priority systems built confidence in the workflow. Preflight validations eliminated the risk of last-minute failures. With careful planning and the use of Postgres’ built-in replication mechanisms, zero-downtime upgrades are feasible for major Postgres version changes.
We once again want to thank the PostgresAI team. There are also some future items we would like to explore with them, including completely reversible upgrades just in case an issue is detected some time post-upgrade, and plan flip analysis that compares behavior of planner and executor on old and new versions of Postgres.
You can also read about our zero-downtime db shard.
If you have any questions about the upgrade process, you can get in touch with us in our developer Discord.
Appendix: More details on unique IDs, sequences, and why they matter
We create the majority of our tables with primary key sequences, something like:
CREATE TABLE my_table (
id BIGSERIAL PRIMARY KEY,
name TEXT NOT NULL
);where the primary key is autoincremented for us when creating a new record.
This is great for when we create new records we can lean on Postgres to make sure the <inline-code>id<inline-code>’s are unique. A typical flow would look like:
INSERT INTO my_table (name) VALUES ('Alice');
INSERT INTO my_table (name) VALUES ('Bob');
INSERT INTO my_table (name) VALUES ('Charlie');Where the sequence starts at <inline-code>1<inline-code> and by the end would be at <inline-code>3<inline-code> with the next insert getting <inline-code>id:4<inline-code>.
However if an <inline-code>id<inline-code> value is provided then the sequence will not be automatically incremented:
INSERT INTO my_table (id, name) VALUES (4, 'Grace');The sequence would still be at <inline-code>3<inline-code> with the next value being <inline-code>4<inline-code>. And if we added a new row:
INSERT INTO my_table (name) VALUES ('Dennis The Menace');we would get a primary key violation because we would be trying to insert a second record with <inline-code>id:4<inline-code>
In logical replication, the whole row is copied over including the <inline-code>id<inline-code> column. Because the <inline-code>id<inline-code> column is provided when we insert a new row the underlying sequence is not incremented like the example above. So when the candidate instance gets promoted we need to ensure that the sequences on the candidate are the same or ahead of the sequences on the primary to avoid any primary key violations.
When we did the cutover we also incremented each sequence by a fixed amount to make sure that we didn’t get hit by an off-by-one error: <inline-code>candidate_sequence = primary_sequence + 1000<inline-code>
Note: Setting sequences can take a long time if you have a lot of tables, we updated the sequences in-line but this can also be done pre-cutover to save time while the DB’s are paused. If you do it before the actual cutover your increment value just needs to be bigger than the number of rows that will be created in the primary between the sequence change and the cutover.